
EN
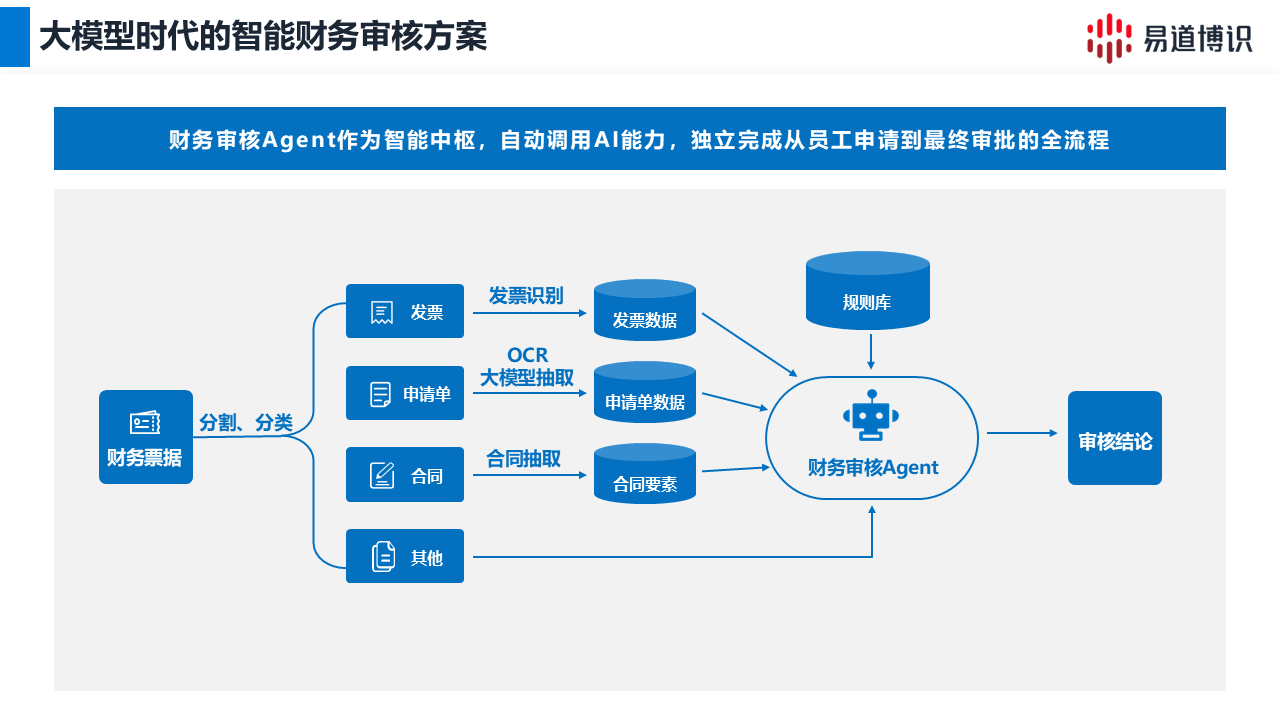
發票、合同、銀行回單,格式千變萬化。處理這些非標長尾文檔,正成為財務與運營部門極大的痛點。
OCR識別準確率低,,頻頻錯漏。系統認不出,最終只能靠人眼看。這導致了居高不下的二次人工核對成本,效率不增反降。
那么,全部接入通用大模型就能解決嗎?答案是否定的。盲目堆砌大模型,企業將面臨兩個新問題。一是高昂的算力成本。二是高頻處理場景下的排隊與響應延遲。
在此背景下,一種更為務實的方案脫穎而出,“大小模型協同”的智能文檔處理方案,兼顧準確率與算力成本。
在升級智能文檔處理能力時,企業通常會有以下瓶頸。
1. 二次人工成本居高不下
一線業務每天產生大量非標單據。傳統的模板識別技術缺乏泛化能力。面對異構表單,關鍵信息抽取極易失敗。業務人員不得不投入大量時間進行手工核對與補錄。
2. 高并發與長尾解析的矛盾
高頻并發遇上長尾疑難,系統極易崩潰。遇到月末結算高峰,傳統架構無法動態調配計算資源。此時,系統不是排隊堵塞,就是響應超時。
3. 數據斷點引發合規風險
早期系統往往是模塊化拼湊。掃描歸檔一套系統,OCR識別一套接口,各環節相互割裂。數據鏈條存在嚴重斷點。在后評估或合規審計時,審核結論難以有效追溯到原始影像。這極大地增加了企業的合規風險。

面對上述痛點,單一模型已無法勝任。行業內的領先方案,正在走向精細化的協同架構。以易道博識推出大小模型協同,給出了新的文檔處理思路.
易道博識創新落地了“智能路由抽取”機制。文檔輸入后,系統會自動判斷并分流。
●小模型處理高頻文檔:針對標準化證件及定式票據,由傳統OCR模型負責。它主打批量抽取,保證秒級響應。月末并發高峰,也能輕松應對。
●大模型攻堅長尾文檔:針對復雜的非標單據,系統自動路由至大模型。利用大模型的泛化理解能力,進行深度精準抽取。
在這套協同機制的支撐下,不論文檔格式多復雜,關鍵信息的提取準確率均躍升至99.5%以上。
引入大小模型協同的智能文檔系統,不僅提升了OCR的可用性,更實現了端到端業務閉環的效率飛躍。
1. 零代碼配置,規則“分鐘級上線”
過去,只要監管出臺細則,或者內部風控策略發生變動,企業就得向IT排期。例如修改交通報銷額度限制,需要重新編寫校驗代碼,業務響應極慢。
在易道博識DocFlux中,前端業務人員憑借自然語言,即可進行可視化配置。輸入“高鐵不得高于二等座限額”,邏輯驗證節點即刻生成。規則一經設定,即刻生效。真正實現了業務規則的零代碼、分鐘級上線。
2. 全程可追溯,確保合規透明
所有的數據抽取明細和審核風控信號,全都在可視化看板中直觀呈現。得益于引擎保留的信息位置錨點,哪怕是一處細微的審核異常,也能直接回溯,并精準高亮在原位影像上。
每一項機器核驗依據,都清清楚楚。這完全滿足了嚴監管行業對審計可解釋性的嚴苛要求。
1. 引入大小模型雙引擎,成本高嗎?
不會。這正是該架構的核心財務優勢。日常海量高頻任務由算力占用極小的小模型負責識別。只有非標長尾文檔,才會路由至大模型。因此,整體算力消耗遠低于純大模型方案。
2. 這套架構,能否融入現有業務系統?
完全可以。易道博識的這套方案采用組件式設計,提供標準化的業務接口。無論您是想替換掉工作流中某個“卡脖子”的節點,還是計劃重構一整套從業務采集到核心ERP歸檔的一體化平臺,它都能以靈活的微服務形式快速集成。





