
EN
傳統財務審核流程往往伴隨高額的二次人工成本與合規溯源的脫節。依靠手動錄入、肉眼比對和硬編碼規則校驗的模式,不僅耗費大量審計和財務人員的工時,也難以應對復雜的多發票、多回單場景。
易道博識智能文檔工作流(DocFlux),通過“大小模型協同抽取+自然語言配置規則”,為財務智能審核場景提供了一套標準化的落地方案。
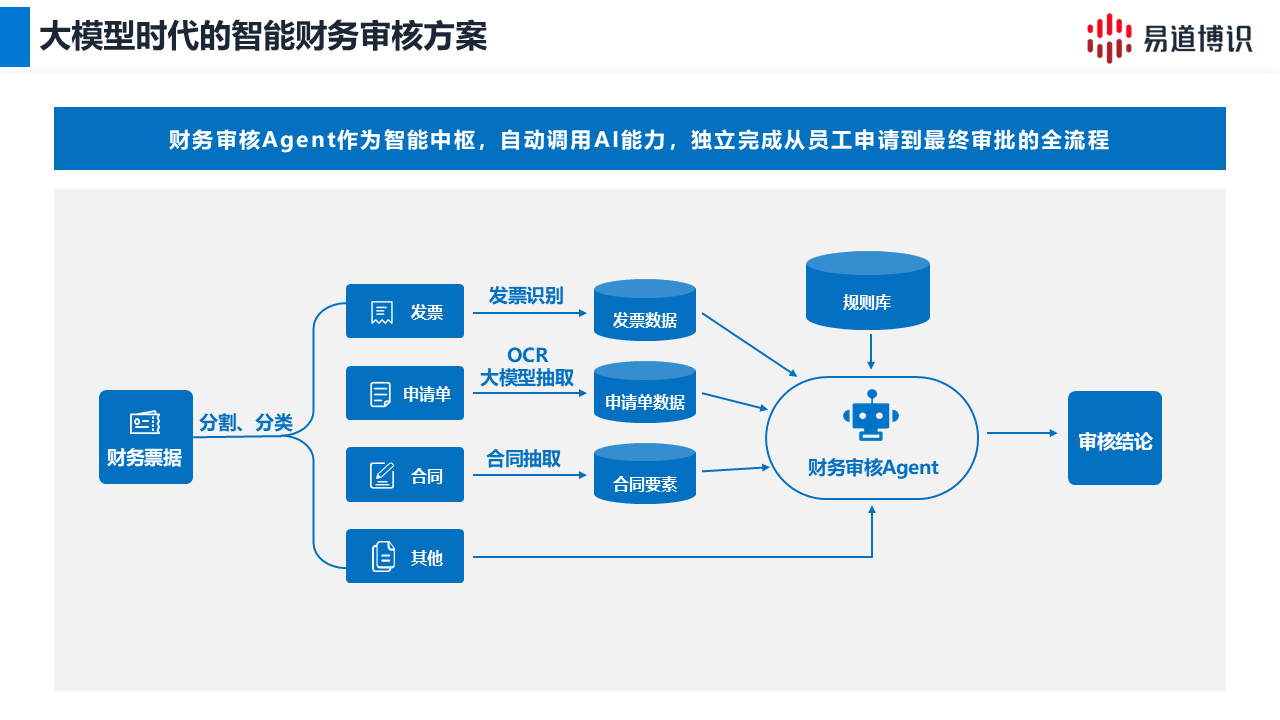
在處理發票、合同、銀行單證等綜合審核場景時,現有系統通常面臨以下業務問題:
1、流程斷裂,人工成本高
傳統的報銷系統與財務核算系統之間缺乏有效的端到端數據連接。前端業務提交付款申請后,財務人員依然需要逐張核對應收應付原始單據與系統錄入的數據對應關系,導致采集、識別和比對流程被嚴重割裂。
2、規則硬編碼導致系統響應滯后
內部差旅制度調整或外部稅務政策變化時有發生。傳統的審核引擎多采用代碼硬編碼規則,一旦差旅標準或報銷額度發生變化,必須依賴 IT 團隊排期開發修改。這種響應滯后在業務高峰期往往會造成長時間的審核阻塞。
3、審計合規要求的溯源難題
外部審計和內部合規風控要求每一筆開支都能清晰溯源至底層物理單據。大量傳統系統難以記錄完整的圖文數據映射,在面臨外部調取報銷原始單據以驗證校驗依據時,核查過程耗費工時,極易造成解釋不清的合規管理風險。
4、長尾非標單據的校驗識別瓶頸
企業日常流轉中包含了定額發票、手寫收據、異地住宿單、隨貨同行單等繁雜版式。單純依賴小模板模型,在這類非標、長尾票據上的字段級抓取準確率無法達到生產要求,導致后續數據校驗頻繁報錯。
面對上述困境,智能文檔工作流(DocFlux)通過底層 AI 模塊的重構,專門提供了貼合真實業務環境的能力設計。
1、智能拆套分類:規避源頭雜亂
針對人員打包上傳的雜亂業務憑證包,系統降低了對人工預處理的依賴。平臺最高支持 200M 大文件(例如密集掃描件的 PDF 和壓縮包)高并發執行,對文件包自動實現影像分割、拆套與結構化歸檔。
2、大小模型協同:攻克長尾非標特征
系統底層架設了大小模型智能路由引擎進行抽取。標準化的高頻發票表單交由小模型進行毫秒級結構化,而低頻長尾高度非標的業務單據則由參數量更大的大模型實時接管。該協同架構使得各類非結構化文本的提取準確率達到 99.5% 的高位指標。并且支持 200 多種國內常見票種并行處理,應對月結高峰表現穩健。

3、自然語言規則配置,敏捷迭代
負責實質性審核的財務業務人員,無需研發支持即可在可視化頁面利用自然語言構建強制校驗邏輯。通過輸入諸如“員工住宿費一線城市每日不超600元”、“交通報銷禁止晚8點前打車”等口語化準則。在發布后系統可實現在分鐘級別直接生效執行,同時完成數據邏輯驗證和業務合規控制。





