
EN
我們的答案是:不能。大模型的優勢固然顯著,但小模型的價值同樣不可替代。二者的深度融合,才是現階段 OCR 領域的最優解。
首先來看下OCR技術的演進。
傳統模式識別時期:該階段的 OCR 技術主要基于模板匹配和特征提取的方法來實現字符識別。具體來說,就是將待識別的字符圖像與預先定義好的模板進行匹配,通過計算相似度來確定字符的類別。這種方法在處理簡單、規范的字符時表現尚可,但對于復雜的字體、手寫體以及受到噪聲干擾的圖像,其識別準確率往往不盡人意。
此外,傳統 OCR 技術還依賴大量的人工特征工程,需要手動設計和提取字符的特征,這不僅耗時費力,而且難以適應多樣化的應用場景。
深度學習應用時期:隨著卷積神經網絡(CNN)、循環神經網絡(RNN)及其變體長短期記憶網絡(LSTM)等深度學習技術的發展,使得 OCR 從手工特征提取的模式轉變為自動學習高級語義特征的模式,大大提高了識別的準確率和魯棒性。
CNN 能夠自動學習圖像中的局部特征,通過多層卷積和池化操作,有效地提取字符的邊緣、紋理等特征信息;RNN 和 LSTM 則擅長處理序列數據,能夠捕捉字符之間的上下文關系,對于識別連續的文本具有顯著優勢。 它能夠處理各種復雜的場景,如自然場景中的文本識別、手寫體識別、多語言混合文本識別等,為 OCR 技術的廣泛應用開辟了新的道路。
核心步驟包括文字檢測、文字識別及信息抽取,每個步驟都由一個或多個深度學習模型完成。
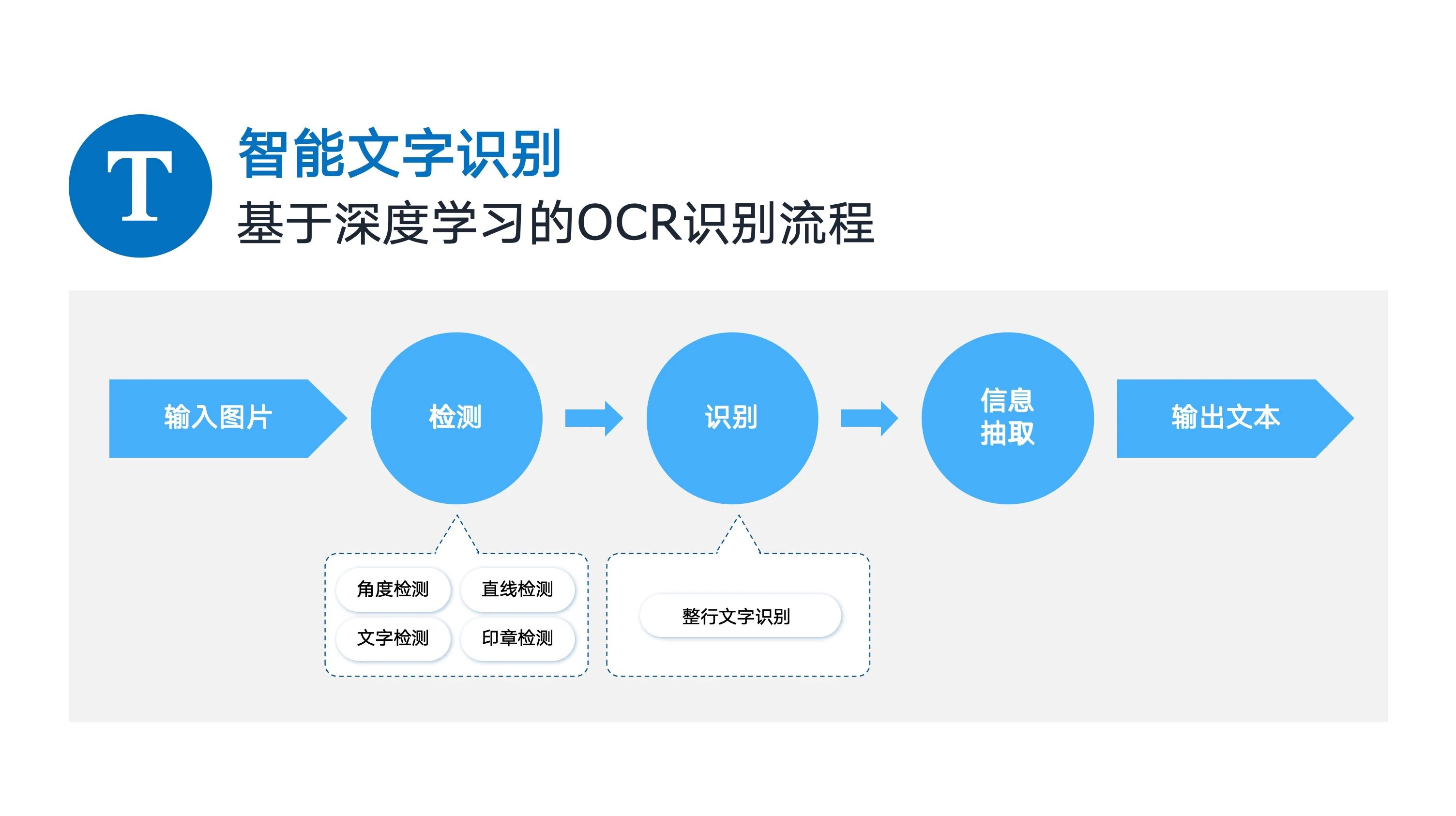
大模型時代的OCR識別:大模型的核心架構多基于 Transformer,這一架構憑借自注意力機制(Self - Attention),能夠有效捕捉數據中的長距離依賴關系,極大地提升了模型對上下文信息的理解與處理能力。
在OCR領域,大模型的應用主要分為兩條技術路線:
路徑一:OCR小模型 + 純語言大模型,該路線是 “傳統 OCR 基礎能力 + 大模型語義理解能力” 的組合方案:先用輕量級 OCR 小模型完成圖像到原始文本的轉換,再用純語言大模型(僅處理文本輸入)對原始文本進行結構化抽取、糾錯或語義解析。
路徑二:多模態大模型。多模態大模型是“圖像輸入→文本輸出” 的端到端解決方案,其核心能力是同時理解圖像的視覺特征(文字形狀、位置、布局)和語言的語義信息,直接從圖像中完成 “識別 + 理解 + 抽取” 的全流程,無需顯式拆分 OCR 和語義處理環節。
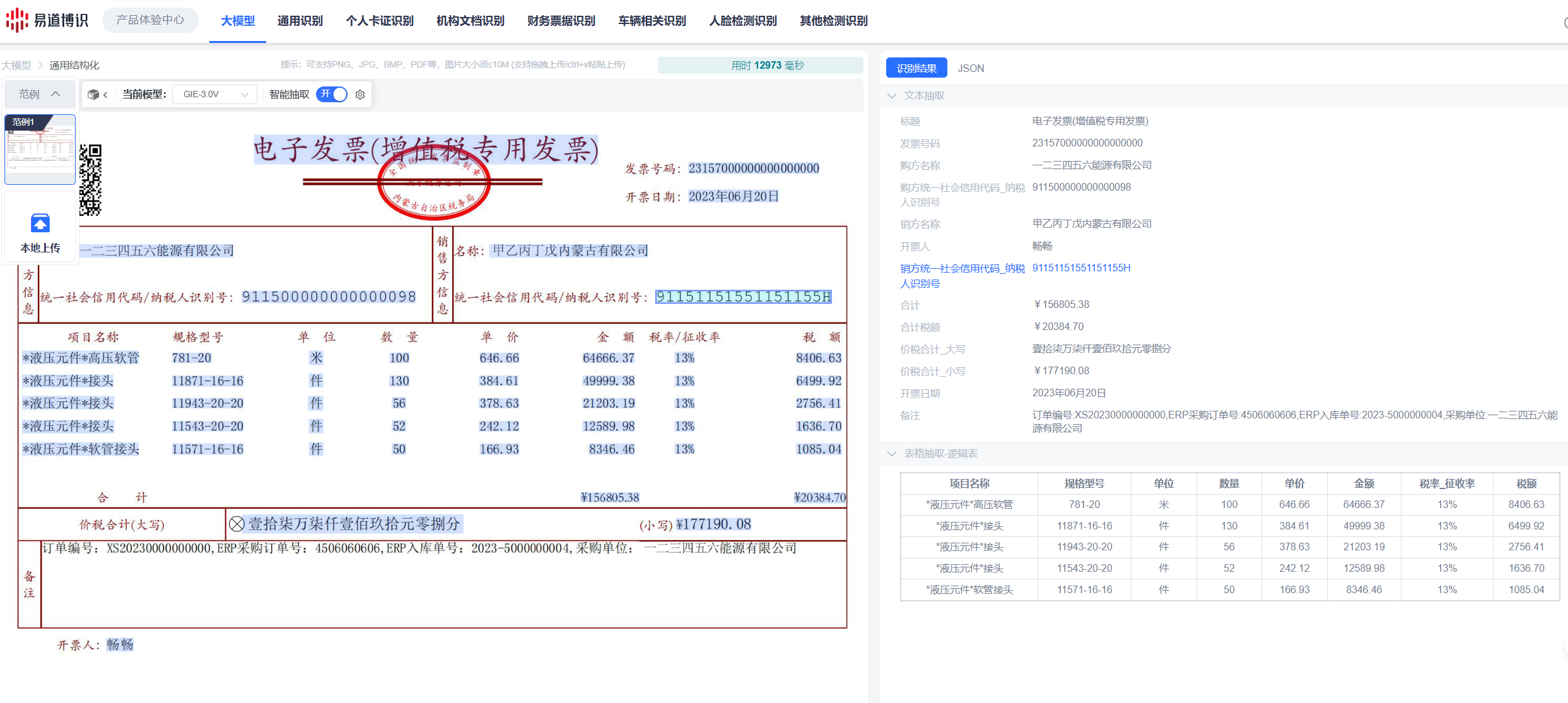
大模型文檔識別的優劣勢比較
大模型識別的優勢在于:
識別流程簡化:過去需要多個模型串聯才能完成的任務,現在一個“端到端”的大模型就能搞定。這不僅減少了開發的復雜性,也避免了每個環節傳遞時可能產生的誤差累積。比如識別一張身份證,過去要圖像校正、文字定位、識別、字段抽取好幾步,現在直接把圖片發給大模型,姓名、地址、身份證號一次性抽取出來。
泛化能力強:大模型在新場景下的適應能力非常強。比如銀行交易回單,每家銀行的格式都不一樣,過去可能需要對每一種格式都做針對性的模型訓練,現在用大模型,不需要專門訓練,就能達到較為理想的識別效果。
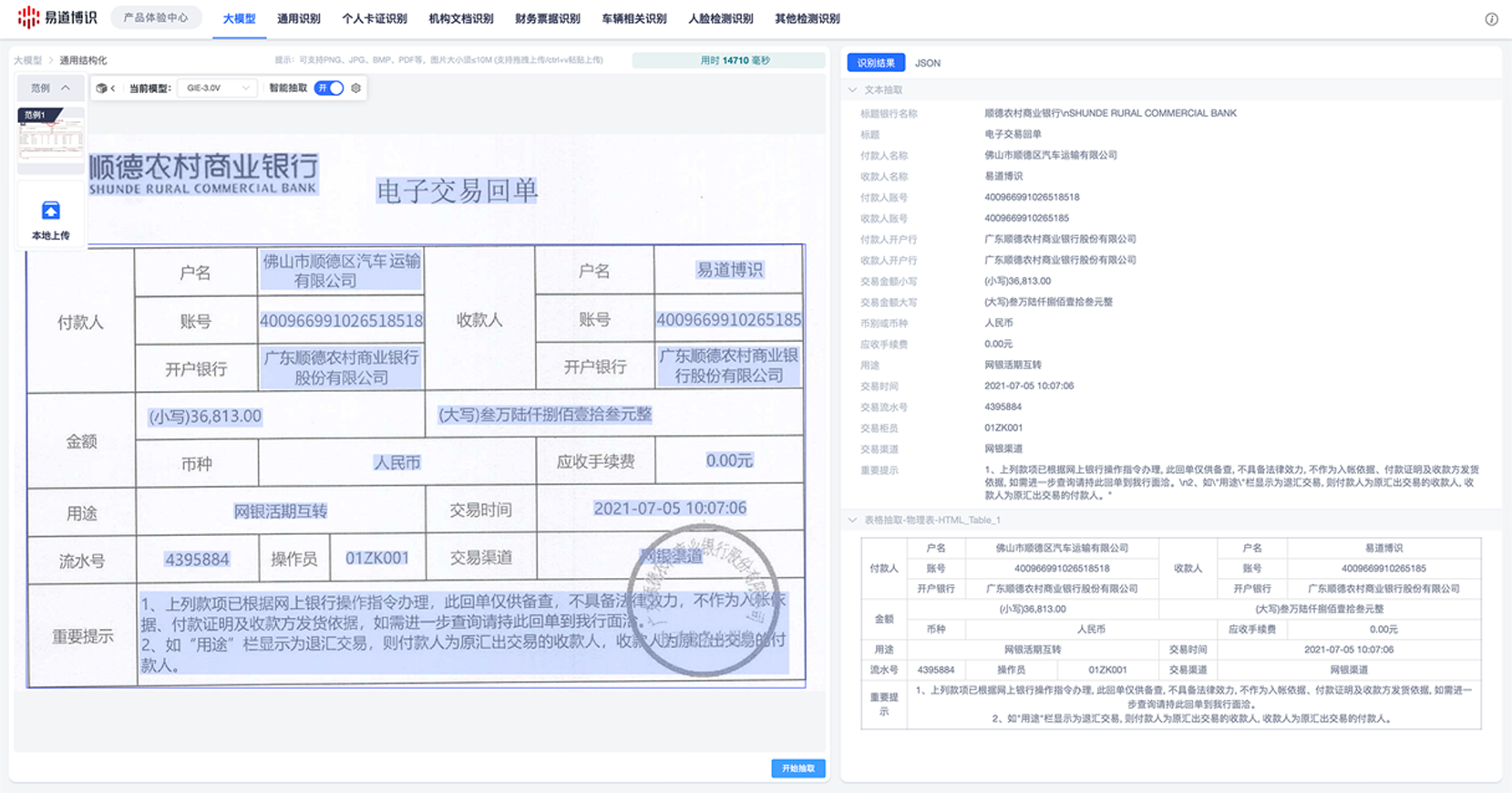
語義理解與結構化:大模型能讀懂文字背后的邏輯關系,尤其是在處理合同、招股書、法律文書這類長篇、復雜的文檔時,優勢明顯。
大模型為OCR帶來了新的可能性,但也有明顯的局限。
1. 高成本
首先是訓練成本高。訓練一個千億參數的大模型,需要幾十甚至上百臺頂級的GPU服務器,僅硬件采購,就是數百萬美元的投入。
其次是數據,高質量的標注數據是按條計費的,一個覆蓋多場景、多語言的大模型,數據成本就能達到上千萬人民幣。最后是時間和人力,整個訓練周期可能長達數月,需要一個算法團隊不間斷地監控和調優。
而且模型訓練好只是第一步,在實際業務中使用(也就是“推理”)的成本同樣驚人。大模型的計算量巨大,導致它的推理速度非常慢,處理同一個OCR任務,耗時可能是小模型的10到100倍。這意味著,用大模型替換小模型,并且還要維持原有的業務處理效率,硬件投入也要翻10到100倍。對于像每天調用量上千萬次的高頻業務,用大模型基本不現實。
2. 高延時
由于大模型的復雜結構和龐大參數規模,在批量處理場景中,大模型的并行計算能力受限于內存帶寬,單位時間內處理的樣本數量遠低于傳統模型。一臺服務器在1分鐘內,傳統模型可處理5000張圖像,而大模型僅能處理500-800張,吞吐量差距高達6-10倍。
3. 精度較低
這可能是最反直覺的一點。大模型在理解整段文本的語義上很強,但在最基礎的、單個字符的識別準確率上,有時候反而不如小模型。
● 生僻字、特殊符號識別差:工程領域的專用符號,古籍里的生僻字等,因為在海量的訓練數據里占比太小,大模型“見得少、學得差”,識別準確率可能比專門優化過的小模型低很多。
● 相似字符容易混淆:比如“己、已、巳”,或者“b、d、p”。大模型太依賴上下文去“猜”,反而忽略了字符本身的細微差別。在對準確性要求極高的場景,這種錯誤達不到上線標準。
4. 優化難
小模型如果識別某個字效果不好,我們可以針對性地調整、優化。但大模型是個“黑箱”,內部極其復雜。想針對某個特定問題做微調,需要投入海量的新數據,否則很容易把模型“改壞”,在A場景的優化導致了B場景的性能下降。出了錯,也很難定位到具體是哪個環節的問題。
5. 幻覺問題
這是大模型特有的問題,它會“創造”出圖像里根本不存在的內容。比如圖片上明明是“張三”,因為它在某個上下文里學過“張王”,就可能在圖像有點模糊的情況下,自作主張地識別成“張王”。這種“幻覺”現象,源于它強大的語義聯想能力,但在要求絕對忠于原文的OCR任務里,這是個致命缺陷。
應當意識到,當前大模型在部分應用中存在的問題,為小模型提供了明確的應用空間。小模型的存在并非技術迭代中的過渡形態,而是基于實際應用場景需求的“最優解”。
其核心價值體現在三個維度:
● 成本敏感場景的剛需選擇: 在高頻OCR識別場景,若采用大模型,硬件成本會成數十倍地增加。例如,金融機構處理身份證識別業務,每日調用頻率可達百萬甚至千萬次,采用大模型在成本和效率上均不具備可行性。
● 邊緣設備的適配核心: 在手機、掃描儀、工業傳感器等邊緣設備中,小模型憑借低內存占用(通常低于100MB)、高運行效率(單樣本處理耗時低于20毫秒)成為剛需。例如,手機端的“拍照識別翻譯”功能需在0.5秒內完成識別與翻譯,大模型因網絡延遲過高(通常超1秒)難以適配,而小模型則能滿足實時性要求,目前在該場景中小模型的市場占比超過95%。
● 特定場景的精度保障: 在印刷體識別、車牌識別、財稅票據識別等標準化場景中,小模型通過針對性優化可實現99%以上的識別精度,高于大模型。例如,身份證需精準區分“瑋”與“偉”、車牌號需要區分“A”與“4”等相似字符,小模型可通過定制化特征提取器實現高效識別,而大模型因過度依賴通用語義推測,實際應用中錯誤率是小模型的5-10倍。

正是基于小模型上述的核心價值,從市場需求、技術演進和商業成本結構來看,其在未來3-5年內仍將占據OCR領域的主導地位。
● 碎片化場景的覆蓋能力不可替代: OCR應用場景呈現高度碎片化特征,從銀行票據、醫療病歷到工業零件編號、古籍文字,不同場景對識別速度、精度、成本的要求差異顯著。小模型可通過“場景定制化”模式快速適配細分需求,例如針對手寫病歷的小模型可優化連筆字符識別,針對工業零件的小模型可增強對油污、磨損字符的魯棒性。相比之下,大模型追求“通用性”,難以在每個細分場景中達到最優性能,目前其在碎片化場景中的市場份額不足10%。
● 技術迭代的輕量化趨勢支撐: 小模型的技術迭代正朝著“更高精度+更低資源消耗”的方向發展。例如,基于知識蒸餾的小模型可繼承大模型的部分語義理解能力,同時保持輕量化優勢;基于神經架構搜索(NAS)的小模型能自動優化網絡結構,在精度與效率間實現更優平衡。數據顯示,2024年主流輕量化OCR小模型的識別精度較2022年提升8%,而計算資源消耗則下降40%,進一步鞏固了其市場地位。
● 成本與效率的平衡難以被超越: 在商業應用中,總擁有成本(TCO)與效率是企業決策的核心指標。對于年處理量低于1000萬張的中小型企業,小模型的TCO僅為大模型的1/5-1/10,且部署周期僅需1-2周,遠低于大模型的3-6個月。
即便是大型企業,在業務場景中也更傾向于選擇小模型,例如某大型電商平臺的快遞面單識別業務,由大模型換為小模型后年成本降低800萬元,同時識別精度可保持在99.5%以上。
技術實現上,可通過級聯融合、混合部署及動態路由來實現大小模型的融合:

級聯融合:先使用OCR小模型進行圖像文字的初步識別,快速提取出文本的基礎信息,然后將識別結果輸入到語言大模型中,大模型利用其強大的語義理解和推理能力,對識別結果進行進一步的理解、分析和處理,如進行內容總結、結構提取、問答等操作。這種方式結合了小模型的高效性和大模型的強理解能力。
混合部署:根據業務場景的需求(如實時性、精度、成本),顯式分配大模型或小模型的任務,兩者獨立運行但協同互補。高頻的標準證件、票據使用專用小模型識別,保證識別速度和低成本優勢,非標、復雜長文檔使用大模型識別,保證效果及泛化能力。
動態路由:根據輸入內容的實際情況,自動選擇大模型或小模型,實現智能化的資源分配。先通過一個分類模型實現對文檔的精準分類,根據文檔類型,決策調用大模型或者小模型完成識別。
易道博識DeepIDP平臺,采用大小模型協同架構,為企業提供兼具成本效益與高精度的解決方案。
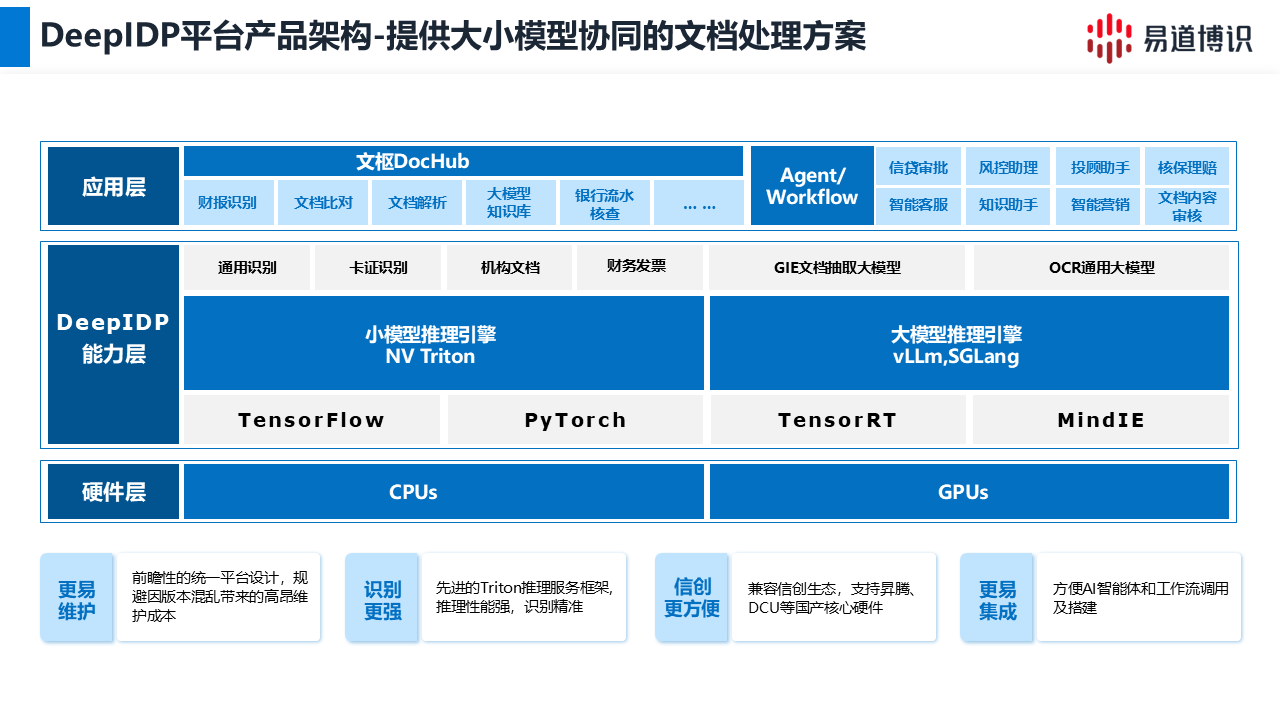
在本架構中,支持大模型與小模型級聯融合與混合部署,并可根據任務需求,調用不同的識別功能,使用內置的文檔分類功能,實現大小模型的動態路由。
展望未來,隨著算法的演進和硬件算力的提升,大模型與小模型的界限也將逐漸模糊:大模型正向輕量化方向發展,以降低部署成本和推理延遲;而小模型則在硬件支持下,參數規模和能力邊界也在不斷擴展。這種雙向演進,最終將促成二者在更深層次上的形態融合。






