
EN
在特殊發(fā)票版式識別方面,越來越多的公司開始使用OCR大模型,通過輸入提示詞,利用大模型強大的泛化能力,無需預(yù)設(shè)模板即可精準(zhǔn)抽取任意發(fā)票版式信息,從根本上解決了傳統(tǒng)OCR面對新版式時識別率低、維護成本高的問題。
傳統(tǒng)的OCR識別解決了從“手動”到“自動”的問題,但其固有的局限性在今天愈發(fā)明顯。
1、OCR原理解釋
傳統(tǒng)系統(tǒng)通過學(xué)習(xí)海量樣本,為每一種發(fā)票(如增值稅發(fā)票、火車票、定額發(fā)票)預(yù)先訓(xùn)練一個專用識別模型。當(dāng)接收到圖像時,系統(tǒng)會先進行版式匹配,然后調(diào)用對應(yīng)的模板進行字段切割和識別。
2、OCR識別新版式有什么局限性?
● 新增版式識別困難:每當(dāng)出現(xiàn)一種新的或不常見的發(fā)票版式,就需要重新收集樣本、人工標(biāo)注、訓(xùn)練新模型。整個過程耗時數(shù)天甚至數(shù)周,無法敏捷響應(yīng)業(yè)務(wù)變化。
● 維護極其復(fù)雜:企業(yè)需要管理和維護數(shù)十個不同的模型和API接口,不僅導(dǎo)致硬件資源利用率低,也讓技術(shù)維護成本居高不下。
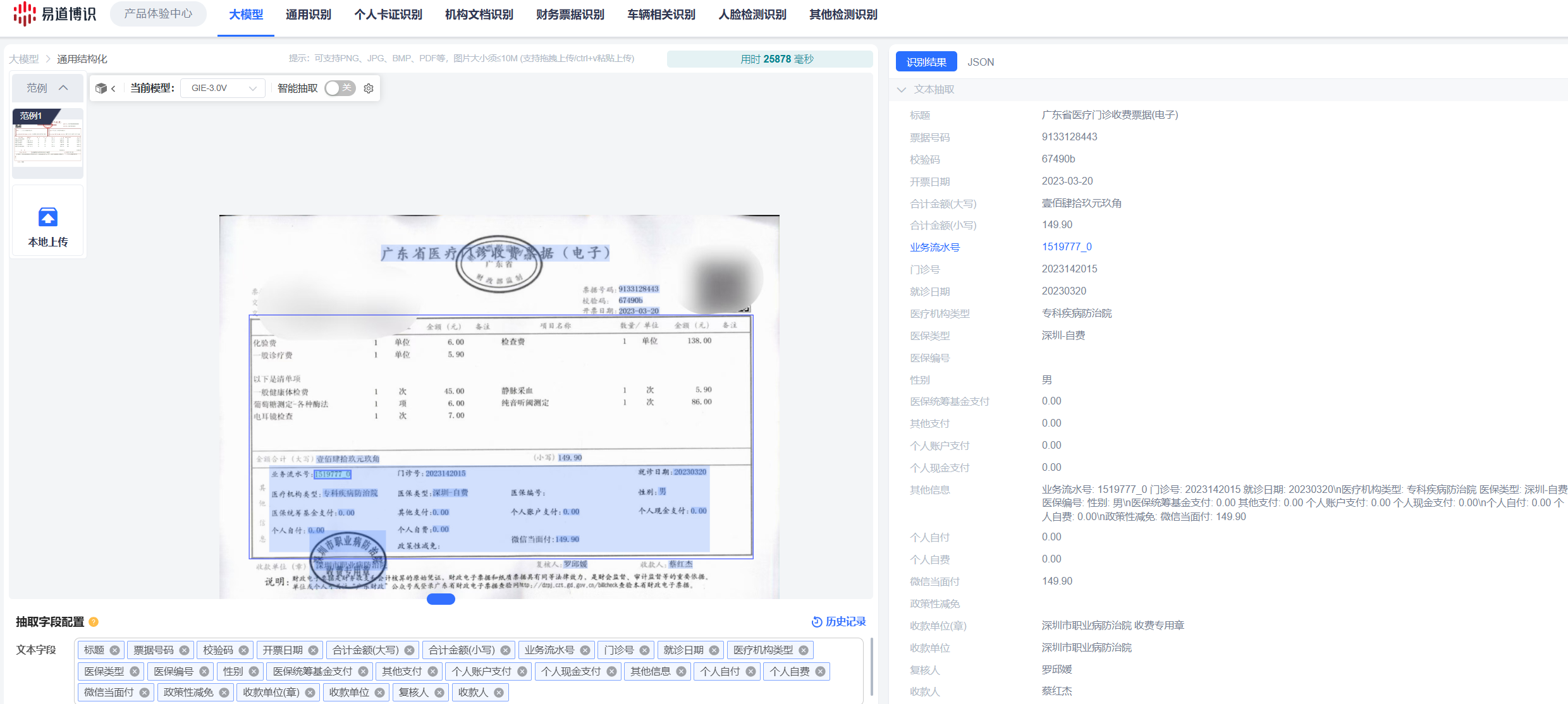
OCR大模型的出現(xiàn),標(biāo)志著文檔識別技術(shù)從“專用模型”向“通用智能”的根本性轉(zhuǎn)變。比如易道博識的OCR大模型,可以幫助企業(yè)實現(xiàn)任意版式文檔字段的識別抽取。
1. 什么是GIE大模型?
GIE(General Information Extraction)是基于海量多樣化文檔數(shù)據(jù)訓(xùn)練的通用信息抽取大模型。它不再依賴僵化的版式模板,而是深度融合了版式布局理解和強大的語義理解能力,能夠像人一樣“讀懂”文檔。
2.它如何解決傳統(tǒng)OCR的痛點? GIE大模型的核心優(yōu)勢在于其無與倫比的通用性和泛化能力。
● 從“多模型”到“一模型”:過去需要為每種文檔訓(xùn)練專用模型,現(xiàn)在一個GIE大模型,通過一個統(tǒng)一的API接口,就能應(yīng)對所有已知和未知的版式文檔識別需求。
● 從“模型訓(xùn)練”到“Prompt配置”:一個常見的誤區(qū)是,認為增加新字段或識別新版式必須進行復(fù)雜的AI模型訓(xùn)練。現(xiàn)在使用GIE大模型,業(yè)務(wù)人員只需通過“提示詞”(Prompt),即可完成新需求配置,上線時間從數(shù)周縮短至幾小時。
● 從“高成本”到“低成本”:統(tǒng)一的大模型架構(gòu)大幅簡化了系統(tǒng)操作,顯著降低了服務(wù)器和人力維護成本。
3. OCR大模型如何保證更高的準(zhǔn)確率?
● 零樣本泛化能力 (Zero-shot):GIE學(xué)習(xí)了足夠多的場景,即使面對從未見過的發(fā)票版式,也能實現(xiàn)高精度識別和結(jié)構(gòu)化提取。
● 強大的語義理解:它能精準(zhǔn)理解復(fù)雜表格(如無線表格、跨頁表格)、多欄版式(如合同、報告)甚至圖文混合的文檔,準(zhǔn)確抽取所需信息。
● 大小模型交叉驗證:舉個例子,在銀行等對數(shù)據(jù)質(zhì)量要求極高的場景,可以創(chuàng)新性地采用“大小模型雙錄”方案。即由傳統(tǒng)小模型和GIE大模型分別識別,系統(tǒng)自動比對結(jié)果。只有在兩者結(jié)果不一致時才推送給人工審核,從而構(gòu)建起數(shù)據(jù)質(zhì)量的雙重保險,極大降低了人力復(fù)核成本。
問題1:OCR大模型的識別準(zhǔn)確率具體有多少?
答:根據(jù)權(quán)威廠商的實測數(shù)據(jù),GIE大模型在核心文檔類型上表現(xiàn)優(yōu)異。例如,處理發(fā)票財稅單據(jù)的實體字段精度可達96%,表格精度達到97%;對于各類企業(yè)合同和報告,精度可達96%(實體)和98%(表格)。
問題2:部署OCR大模型是否需要非常昂貴的硬件?
答:部署方式靈活且成本可控。GIE可以根據(jù)企業(yè)需求部署不同參數(shù)量的模型,支持在主流的NVIDIA GPU(如T4, A10)或國產(chǎn)硬件上進行私有化部署,確保數(shù)據(jù)安全。同時,也支持開箱即用的軟硬一體機交付模式。
問題3:OCR大模型和傳統(tǒng)OCR最大的區(qū)別是什么?
答:最大的區(qū)別在于通用性和靈活性。傳統(tǒng)OCR是“專才”,一個模型對應(yīng)一種版式,新增需求必須重新訓(xùn)練。GIE大模型是“通才”,一個模型通過靈活的提示詞(Prompt)就能適應(yīng)所有版式。






