
EN
保險的理賠審核,長期受制于兩大人工痛點:繁瑣的前端分類錄入,以及復雜的后端規則審核。
先看前端的分類錄入。案件高峰期,理賠人員面對的是海量且雜亂的醫療檔案。門診發票、出院小結、明細清單往往混雜在一起。純靠人工肉眼去逐頁拆分、歸類,再把核心數據逐個敲進系統。這不但耗費極高的基礎工時,也極易產生錄入錯誤。
再看后端的業務審核。進入核賠環節后,面對復雜的免賠額計算與自費藥扣減政策,傳統模式依然依賴人工去逐條比對明細。一旦審核人員疲勞或判定標準不一,就極易引發錯賠、漏賠以及相應的合規隱患。
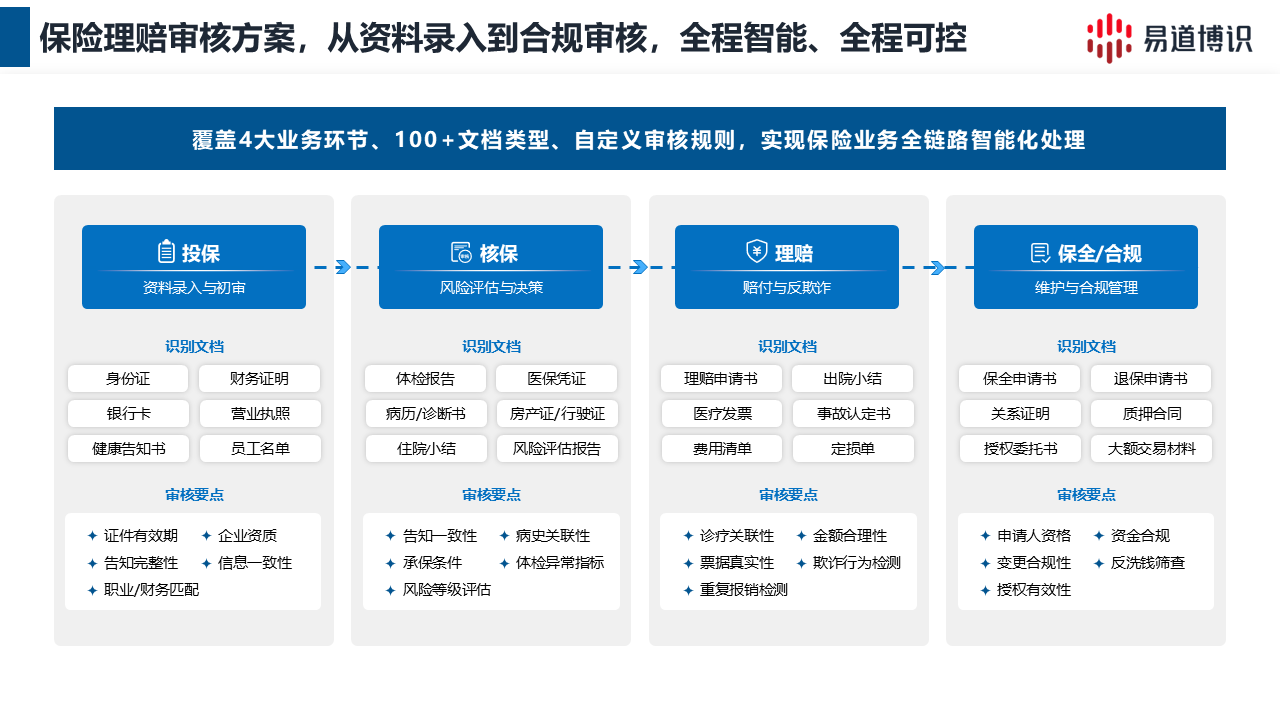
針對這一業務斷點,易道博識推出了智能文檔工作流(DocFlux)。該平臺將“異構單票自動拆套抽取”與“零代碼審核規則引擎”深度融合。系統打通了從單據采集分類、結構化錄入,到最終業務邏輯校驗的端到端流程。
理賠單據天然具有高度的復雜性。不同層級醫院的發票版式各異,病歷帶有大量專業術語,甚至摻雜手寫體。傳統的模板匹配技術在此類場景下完全失效。針對這一難點,系統底層重構了解析邏輯。
1、大小模型智能分流引擎
系統不再采用單一的提取方式,而是根據文檔復雜度進行自動路由分流。對于身份證、增值稅發票等高頻標準票據,系統調用“小模型”實現秒級的高并發處理。對于出院小結、診斷證明等非標的長尾文檔,系統則直接調用“大模型”進行深度的語義解析。這種機制有效平衡了算力成本與識別精度,確保核心字段的綜合準確率超過 99.5%。

2、多維數據交叉校驗機制
系統的核心價值并非僅停留在“把字讀出來”。它同時具備底層邏輯推理的能力。系統能自動完成基礎要素的完整性校驗。更重要的是,它能在系統層面實現跨單據的信息一致性比對。例如:系統會自動核算長達數十頁的清單明細總額,并與門診發票上的對沖金額進行自動校驗。這種多維核驗極大減輕了人工對賬的壓力。
從“輔助人工錄單”走向“全流程自動化直賠”,是對系統端到端能力的真實考量。以下是智能文檔工作流在實際業務流轉中的核心表現:
1、兼容 200 余類復雜票種與高并發處理
前端接入能力決定了系統的吞吐量上限。該產品全面支持壽險、健康險及財險業務線所涉及的 200 余種票據類型。系統涵蓋了病歷、處方箋、乃至財險定損的維修清單。面對打包上傳的理賠卷宗,平臺單文件最大支持 200M 并發解析。系統自動完成材料的拆套分揀與信息抽取,過程無需人工預干預介入。
2、業務主導的零代碼規則維護
保險機構的理算規則變動頻繁。以往調整系統賠付規則需要重寫代碼,周期長且極易阻塞業務。該系統極大地釋放了 IT 資源。業務理賠人員可直接使用自然語言配置規則。只需輸入“住院天數超過30天需強制轉人工復核”或“特定自費藥予以攔截”,系統即可在分鐘級上線生效,實現了真正的業務主導。
3、100% 影像溯源追查
合規審計是保險經營的底線。任何一筆機器拒賠或扣減都必須有源頭依據支撐。系統構建了可視化的數據溯源體系。在業務看板上,對于所有觸發了攔截規則的異常字段,系統都能在原始單據影像上予以高亮標記。所有判定依據一目了然,全面滿足了內外部嚴格的合規審計要求。
1、醫生手寫病歷非常潦草,系統如何保障識別準確率?
準確率不受字跡干擾。系統底層搭載了手寫體增強識別算法。理算遇到印章重疊、折痕或模糊字跡時,大模型會基于醫療上下文進行語義推理。自動校正語法及術語偏差,輸出高置信度的數據。
2、醫療明細清單長達幾十頁,能OCR識別抽取嗎?
堅決阻斷錯行漏列。系統針對非標表格專門應用了版面分析技術。結合視覺語言智能模型,系統能精準還原表單原始的行列層級。即使理賠原件在掃描復印時存在嚴重歪斜或底色干擾。系統照樣實現精準抓取,確保費用明細筆筆對齊。
3、系統對接難嗎?上線是否需要龐大的 IT 實施團隊?
實施周期極短。平臺采用標準的產品化組件封裝,可提供輕量化 API 接口。企業可自主選擇私有化或云端部署。最關鍵的是,后續維護完全去 IT 化。理賠業務人員可隨時用自然語言(對話般的功能)新增或排查審核規則。徹底丟掉沉重的系統開發包袱。





